
Levenshtein Distance
Simple letter counting to choose the best word will not work with more complex differences between national words. A neutral tool is required.
The algoritmic approach to resolve the best mutually intelligible word has no sentiment towards any language. Levenshtein distance algorithm counts letter replacements, instestions and deletion between words and tries to choose the word which is closest to all other words of the same meaning. Preferably the "center word" should have as small distance as possible so the reader can easily understand it from the context.
“ Algoritm Levenshteina nachodi slovo centralne. Jesli slova su velmi razne i ne može najti podobnosti medz slovami, preferuje proste i kratke slova, bo one imaju nemnogo liter. Алгоритм Левенсхтеина находи слово централне. Єсли слова су велми разне и не може найти подобности медзи словами, преферує просте и кратке слова, бо оне имаю немного литер.”
- If the distance is 1 (one letter changed) the understanding is quite easy.
- If the distance is higher (2 letters chaged) the understanding might be more complex.
- At 3 or 4 letters difference the understand requires word memorization just like learning a new language.
| Action | Penalty | Examples |
| Deletion | 1 | albo → abo |
| Insertion | 1 | albo → alebo |
| Replacement | 1 | gde ↔ kde |
| Diacritic | 0.5 0.5 | łosoś ↔ losoś losoś ↔ losos |
| Y/I | 0.5 | bil ↔ byl |
| J/I | 0.5 | dlja ↔ dlia |
| I/Ь | 0.5 | nie ↔ nьe |
| Equivalence | 0 | wasz = vaš czemu = čemu |
This distance is calculated for all words and the word.
The word with the lowest distance to all other words is suggested for use in the dictionary.

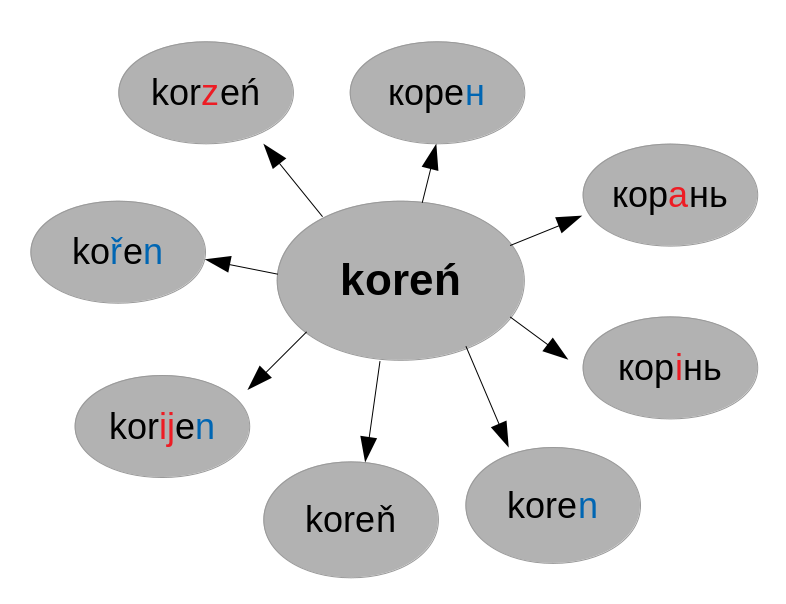
See resolution Table for Cow • Root • Full Dictionary
How to read Levenshtein Transition tables
![]()